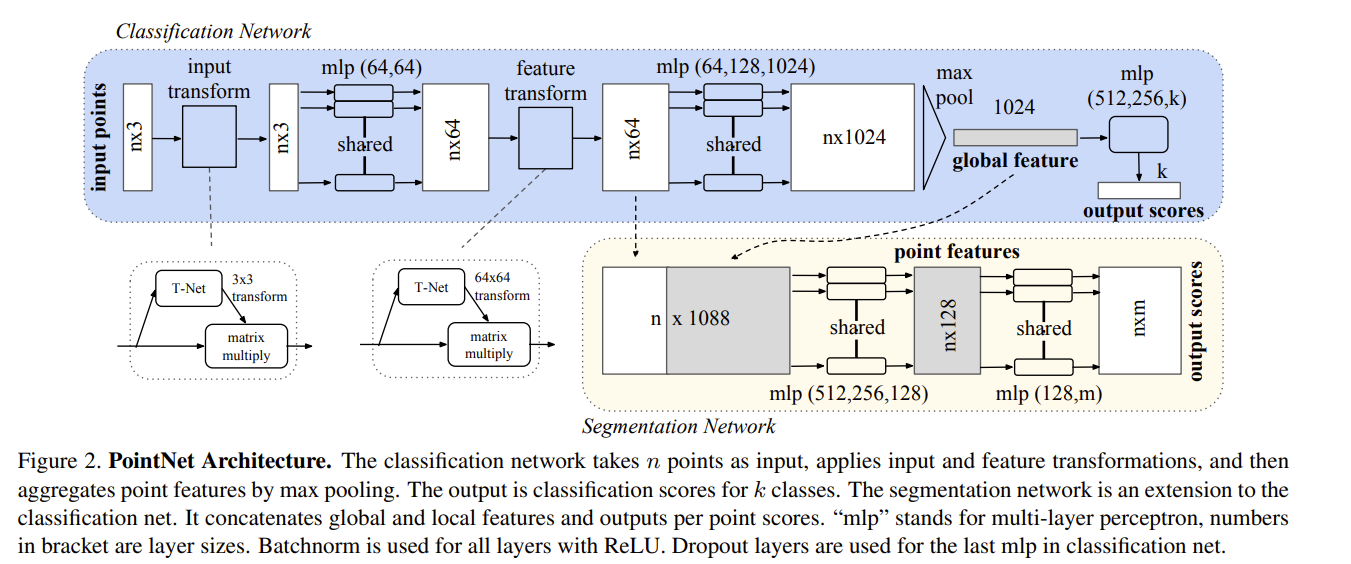
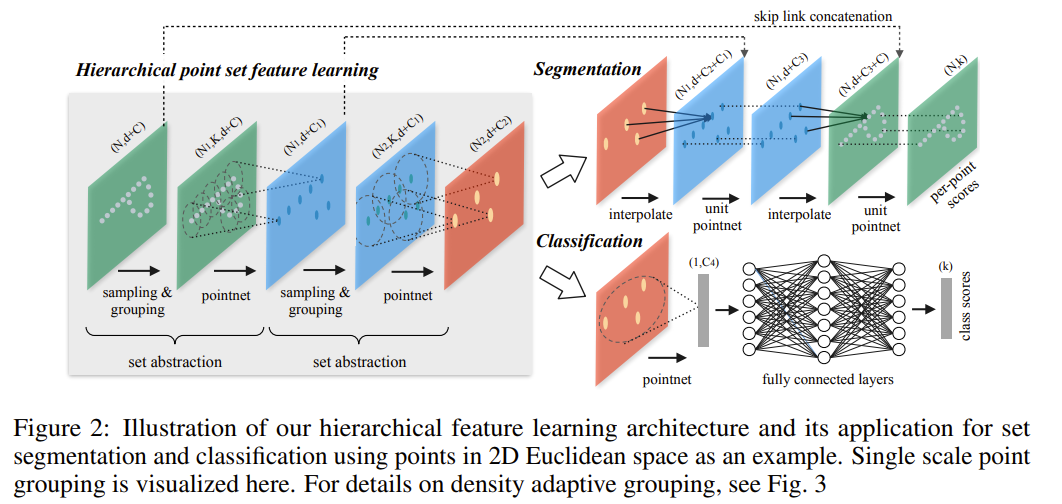
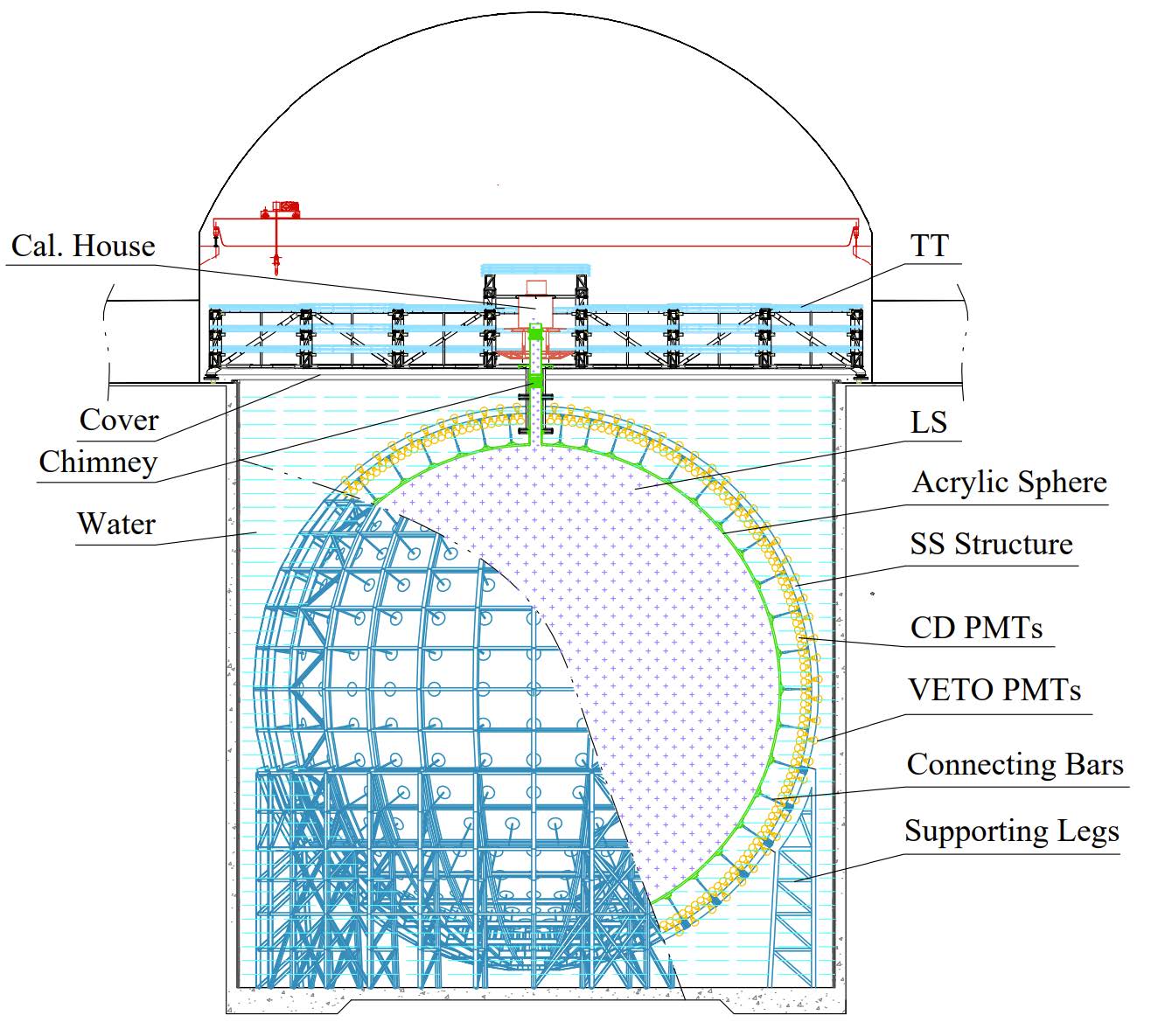
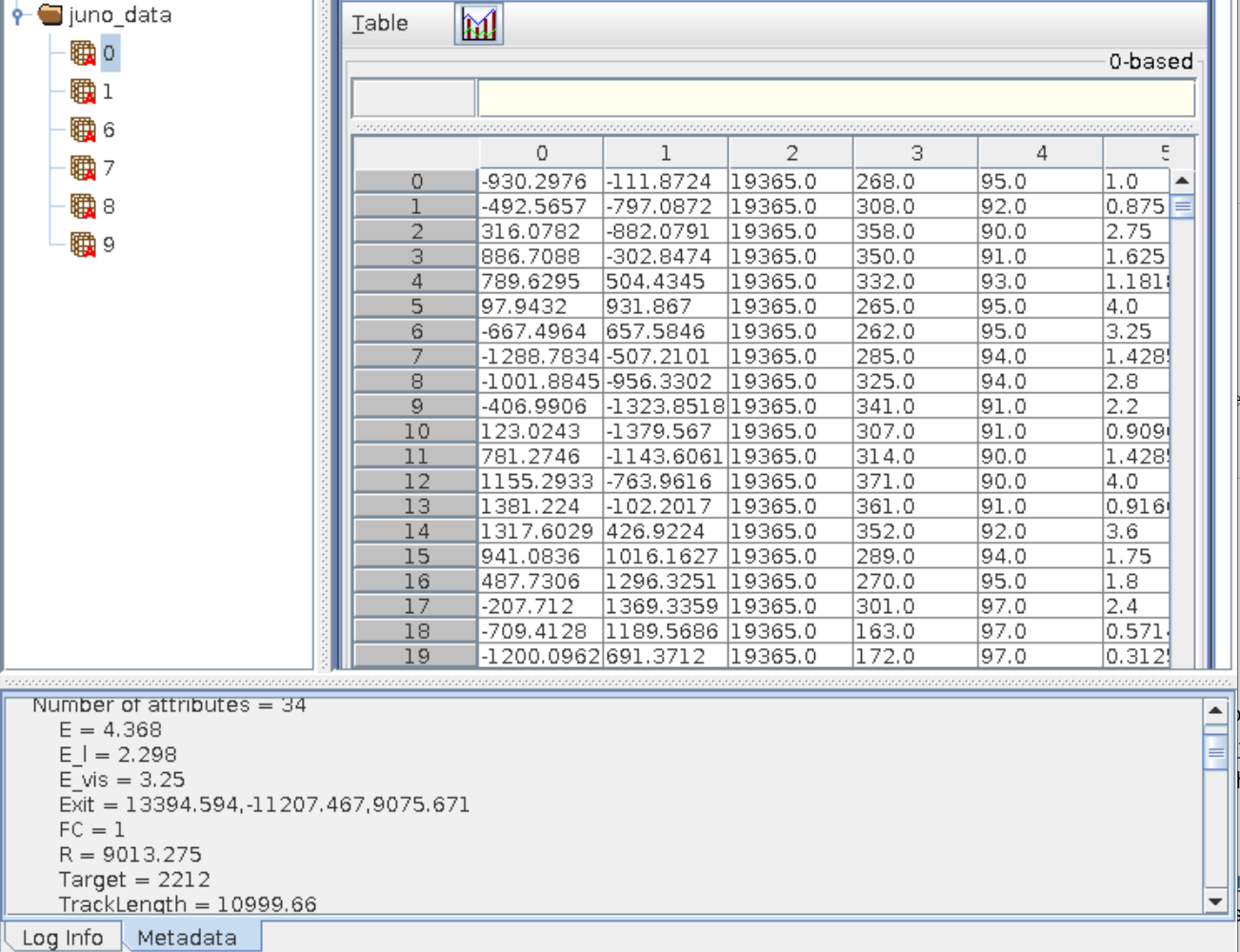
memory usage: 2.7624 GB
Train, Epoch [1/15], Step [100/232], LR=6.12E-05, Loss: 0.59333
Train, Epoch [1/15], Step [200/232], LR=1.24E-04, Loss: 0.53423
Test, Loss: 0.53817
Train, Epoch [2/15], Step [100/232], LR=2.59E-04, Loss: 0.45378
Train, Epoch [2/15], Step [200/232], LR=3.91E-04, Loss: 0.39246
Test, Loss: 0.43332
Train, Epoch [3/15], Step [100/232], LR=5.80E-04, Loss: 0.39894
Train, Epoch [3/15], Step [200/232], LR=7.18E-04, Loss: 0.37493
Test, Loss: 0.45041
Train, Epoch [4/15], Step [100/232], LR=8.72E-04, Loss: 0.34068
Train, Epoch [4/15], Step [200/232], LR=9.53E-04, Loss: 0.30082
Test, Loss: 0.39480
Train, Epoch [5/15], Step [100/232], LR=9.99E-04, Loss: 0.28256
Train, Epoch [5/15], Step [200/232], LR=9.97E-04, Loss: 0.22916
Test, Loss: 0.32349
Train, Epoch [6/15], Step [100/232], LR=9.81E-04, Loss: 0.27618
Train, Epoch [6/15], Step [200/232], LR=9.59E-04, Loss: 0.22244
Test, Loss: 0.27823
Train, Epoch [7/15], Step [100/232], LR=9.19E-04, Loss: 0.27027
Train, Epoch [7/15], Step [200/232], LR=8.80E-04, Loss: 0.23215
Test, Loss: 0.23268
Train, Epoch [8/15], Step [100/232], LR=8.20E-04, Loss: 0.18421
Train, Epoch [8/15], Step [200/232], LR=7.68E-04, Loss: 0.14332
Test, Loss: 0.20657
Train, Epoch [9/15], Step [100/232], LR=6.92E-04, Loss: 0.22331
Train, Epoch [9/15], Step [200/232], LR=6.31E-04, Loss: 0.11996
Test, Loss: 0.17660
Train, Epoch [10/15], Step [100/232], LR=5.48E-04, Loss: 0.17564
Train, Epoch [10/15], Step [200/232], LR=4.83E-04, Loss: 0.10377
Test, Loss: 0.17561
Train, Epoch [11/15], Step [100/232], LR=3.99E-04, Loss: 0.13386
Train, Epoch [11/15], Step [200/232], LR=3.37E-04, Loss: 0.09563
Test, Loss: 0.16085
Train, Epoch [12/15], Step [100/232], LR=2.59E-04, Loss: 0.15647
Train, Epoch [12/15], Step [200/232], LR=2.05E-04, Loss: 0.08841
Test, Loss: 0.15706
Train, Epoch [13/15], Step [100/232], LR=1.41E-04, Loss: 0.12193
Train, Epoch [13/15], Step [200/232], LR=9.89E-05, Loss: 0.08674
Test, Loss: 0.14486
Train, Epoch [14/15], Step [100/232], LR=5.41E-05, Loss: 0.15558
Train, Epoch [14/15], Step [200/232], LR=2.87E-05, Loss: 0.08408
Test, Loss: 0.14363
Train, Epoch [15/15], Step [100/232], LR=7.23E-06, Loss: 0.14586
Train, Epoch [15/15], Step [200/232], LR=4.30E-07, Loss: 0.06049
Test, Loss: 0.14225
Running time: 71.01 min
epoch_best_loss = 0.142251, epoch_best = 14, lr_best = 4.00E-09
Done!